Auteur(s)
Date
Partager
Résumé
Une étude lexicométrique et acoustique d’un objet médiatique alternatif.
Le documentaire Hold-up au prisme de l’analyse de données
Auteur(s)
Date
Partager
Résumé
Une étude lexicométrique et acoustique d’un objet médiatique alternatif.
Cette étude est née d’une volonté d’interroger un objet médiatique alternatif à travers le prisme des méthodologies propres à l’analyse de données. En d’autres termes, si les grilles de lecture théoriques et analytiques permettant de contextualiser et d’appréhender ces objets littéraires ou audiovisuels sont robustes, de la philosophie à la sociologie, en passant par les sciences de l’information et de la communication, il nous semblait intéressant de poser les jalons d’une nouvelle approche permettant d’ouvrir la voie à de nouvelles dimensions dans l’analyse des objets médiatiques alternatifs au format vidéo. Cette démarche est la résultante d’une interrogation que les auteurs de cette étude se sont faite à la suite du visionnage du documentaire Hold-up, rendu public à la mi-novembre 2020, et porte spécifiquement sur l’utilisation du fond sonore au service des ressorts argumentatifs des auteurs de ce documentaire. Après avoir visionné le documentaire, nous nous sommes ainsi interrogés sur la place occupée par la musique de fond, qui accompagne de bout en bout le documentaire, avec toutefois des variations significatives en termes d’intensité et de présence. Notre questionnement initial consistait donc à interroger l’utilisation faite de la musique par les auteurs du documentaire et, tout particulièrement, visait à déterminer ce que les ruptures d’intensité signifiaient. En un sens, cette étude vise à étudier de quelle manière les signaux sonores, leur amplitude, leur variation et leur intensité, peuvent être mis au service d’une compréhension d’un sens que, par un jeu de mots plus ou moins heureux, nous pourrions qualifié de caché.
Méthodologie et création du corpus
Cette étude est articulée autour de deux démarches convergentes. L’une centrée sur une analyse lexicométrique et sémantique du documentaire, et l’autre consacrée à une étude que nous qualifierons d’acoustique. Ces deux approches peuvent être traitées de manière autonome, toutefois l’un de nos enjeux méthodologiques consiste à les faire converger, non pas de manière qualitative, mais en ayant recours à des grilles de lecture issues de l’analyse de données. Nous aurions pu, en effet, choisir de ré-associer manuellement des séquences sonores issues de notre analyse acoustique aux passages associés dans le documentaire, mais cela aurait, en un sens, pu donner lieu à des critiques quant à de quelconques biais de sélection. Si nous n’excluons aucunement dans notre travail ce type d’associations qualitatives, pour des raisons d’intelligibilité et de nécessaire contextualisation, nous avons développé une approche permettant d’associer l’étude lexicométrique et acoustique pour réduire au maximum les hypothétiques biais de sélection, ou cherry-picking pour reprendre une terme prononcé, d’ailleurs, par l’un des intervenants dans le documentaire étudié.
Pour mener à bien l’étude lexicométrique, nous avons réalisé de manière automatisée, et via un service en ligne spécialisé, une transcription textuelle du documentaire indépendant sorti le 11 novembre 2020 et produit par Pierre Barnérias, Nicolas Réoutsky et Christophe Cossé.
La transcription obtenue est au format .txt, et nécessite d’être restructurée afin d’être exploitée dans un tableau de données ayant deux entrées :
- L’horodatage, ou timestamp ;
- Le texte.
Analyse de la fréquence des items
De manière liminaire, nous pouvons réaliser une analyse de la fréquence des items récurrents dans le documentaire. Cette démarche a une portée heuristique relativement faible, à ce stade, mais permet, a minima, de s’assurer que la transcription automatisée ne renvoie pas des données non exploitables.
Pour ce faire, nous avons utilisé la fonction unnest_tokens issue du package Tidytext (@Silge2020). Cette fonction permet de procéder à une tokenization, ou segmentation, de notre chaîne de caractères initiale dans une structure du type un token par ligne.
En recodant certaines entrées, qui ont été mal retranscrites par l’outil de transcription automatisée utilisé, nous pouvons ainsi associer une fréquence à nos différents items. À titre d’exemple, les 10 items les plus utilisés par les intervenants du documentaire, auxquels s’ajoutent bien entendu la voix off, sont les suivants :
| words | n |
|---|---|
| virus | 93 |
| monde | 58 |
| chloroquine | 50 |
| gens | 49 |
| masque | 46 |
| personnes | 39 |
| santé | 38 |
| ans | 37 |
| épidémie | 35 |
| hydroxychloroquine | 34 |
Pour analyser plus en avant le séquençage du documentaire, et essayer de mettre au jour différents patterns, nous avons procédé à la création de 12 entrées thématiques. Pour chacune des thématiques que nous avons arrêtées, nous avons créé, sur la base du words frequency ci-dessus, des dictionnaires afin d’essayer de refléter au mieux la réalité des thématiques telles que présentes dans le documentaire. Cette approche n’est pas exempte de biais, notamment dans les choix réalisés par les opérateurs, néanmoins elle permet, dans la mesure du possible, de pondérer les choix réalisés, via un arbitrage contextualisé des items ajoutés aux dictionnaires.
Nos thématiques cadres sont les suivantes :
- Argent et dématérialisation ;
- Bill Gates ;
- Confinement ;
- Élite mondiale ;
- Gouvernement ;
- Grippe ;
- Libertés individuelles ;
- Médias ;
- OMS et laboratoires ;
- Peur et sidération ;
- Protocole Raoult ;
- Vaccins.
Ce choix de 12 sujets peut sembler relativement arbitraire dans la mesure où il résulte d’un travail analytique commun réalisé par les auteurs de cette étude sur la base de leur compréhension du documentaire. Néanmoins, le choix d’une granularité importante (K=12) opposé à celui d’un nombre plus restreint de sujets (K=4 ou K=8), impacte forcément la grille de lecture proposée. Pour essayer de contrebalancer les biais inhérents à notre segmentation thématique, nous avons procédé à une analyse par topic modeling de notre corpus. Le topic modeling est un modèle statistique de machine learning qui permet, notamment dans le cadre de l’exploitation et de l’exploration de données textuelles de mettre au jour, de manière non supervisée et non biaisée par un opérateur humain, des structures sémantiques.
La création de nos topics models et leur interprétation est fondée sur les travaux de la chercheuse américaine Julia Silge, auteure d’un ouvrage de référence sur le text mining en langage R, et plus précisément sur un article, publié en septembre 2018, et une vidéo mise en ligne sur YouTube, en date du 18 décembre 2017. Nous avons suivi, à la lettre et au code, le protocole proposé par Julia Silge pour entraîner, évaluer et interpréter nos topics models créés à partir de notre corpus de données textuelles.
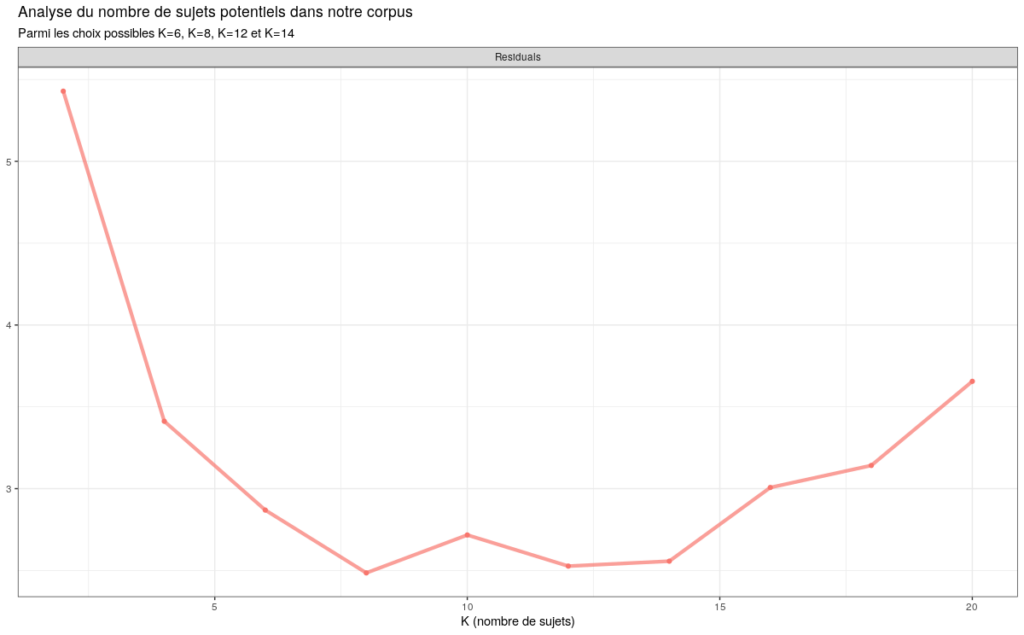
Comme l’indique le graphique ci-dessous, et en suivant les préconisations de Julia Silge, nous observons notamment que les residuals, ou résidus, sont à leur plus bas à K=6, K=8, K=12 et K=14. Un niveau bas de residuals tend, en effet, à indiquer l’existence d’un choix optimal du nombre K de topics.

En poussant plus en avant la partie diagnostic, et en nous intéressant à la cohérence sémantique et à l’exclusivité, et en reprenant à nouveau à notre compte les préconisations de Julia Silge, nous constatons que les modèles à K=8 et K=12 sont, certes moins cohérents d’un point de vue sémantique, mais permettent toutefois de gagner singulièrement en exclusivité.
En d’autres termes, un modèle à K=8 est parfaitement valable et permet de mettre au jour des structures sémantiques pertinentes, néanmoins il pèche en termes de granularité. Contrairement à un modèle à K=12 qui, tout en perdant quelque peu en cohérence, permet de répondre à cet enjeu de granularité. Quoi qu’il en soit, cela donne à penser que notre segmentation thématique du documentaire à 12 sujets, avec la création d’un nombre équivalent de dictionnaires, tend à être validée, en un sens, par une approche de machine learning non supervisée.

Le modèle à K=8 est intéressant car il fait particulièrement bien ressortir la focale mise autour de l’hydroxychloroquine et des études réalisées au cours de l’année 2020 (topic 1), et tout particulièrement au printemps, pour déterminer ou non l’efficacité du protocole proposé par Didier Raoult dans le cadre de la lutte contre le Covid-19. De manière connexe, à travers le topic 7, il permet de mettre au jour, et de singulariser, l’influence suscitée par l’étude, rétractée quelques jours seulement après sa publication, parue au printemps dans The Lancet au sujet de l’hydroxychloroquine. Le topic 4 fait ressortir le discours de plusieurs intervenants du documentaire quant à l’action gouvernementale, et notamment la rhétorique guerrière et belliciste qui a pu entourer la communication de l’exécutif, tout particulièrement au moment du premier confinement. Le topic 6, quant a lui, met l’accent sur la thématique de la peur et des morts liés la pandémie, et ouvre la voie à la problématique du rôle des laboratoires. Les autres topics apparaissent comme relativement peu singuliers et exclusifs, et par là même peu intéressants.
En un sens, les topics 2, 3, 5 et 8 illustrent les limites du modèle à K=8.

Le modèle à 12 sujets ne résout pas tous les problèmes, et continue de proposer des sujets à maints égards trop hétérogènes, néanmoins il permet également de mettre au jour des sujets qui ne ressortaient pas dans le K=8, notamment celui concernant le Covid-19 associé, par l’un des intervenants du documentaire, à un gaz d’origine humaine et militaire (topic 9). De même que ce modèle permet, dans le topic 8, de mettre au jour la séquence centrée sur les critiques adressées au gouvernement et tout particulièrement à l’égard du ministre de la Santé accusé d’avoir eu des “bouffées délirantes” dans le cadre de sa gestion des problématiques soulevées par l’hydroxychloroquine.
Ces éléments une fois posés, et après avoir souligné tout à la fois les qualités et les limites de l’approche non supervisée via le recours au topic modeling, nous présentons ci-dessous les résultats de notre étude par dictionnaire. Cette dernière est beaucoup plus précise, sans être pour autant parfaite, que les résultats proposés par les modèles de machine learning testés ci-dessus, tout en gardant toutefois le nombre K=12 de topics.

La représentation graphique en panneaux ci-dessus représente le nombre d’occurrences des items correspondant aux 12 catégories arrêtées dans le cadre de notre travail de constitution de dictionnaires. Nous avons pris le parti de représenter des séquences de 5 minutes afin, d’une part d’alléger la lecture des différents graphiques, et de l’autre de restituer de manière précise et fine les séquences étudiées. Ce choix a été réalisé après avoir testé des séquences à 1, 5, 10, 20, 25 et 30 minutes, et nous est apparu être le plus adéquat pour représenter les différents phénomènes étudiés.

Pour allez plus loin dans l’analyse, nous avons dans un premier normalisé les valeurs correspondant à chacune des thématiques testées, puis réalisé une série de scatter plots. Afin de mieux faire ressortir les dynamiques apparentes, nous avons utiliser la fonction geom_smooth() en utilisant la méthode LOESS ou LOWESS (Locally weighted regression and smoothing scatter plots). Cette régression, dite non-paramétrique, n’est pas associée à une équation, et revêt un intérêt certain au vu de la configuration de nos nuages de points représentés dans notre série de tableaux Si la construction de ces régressions et les ressorts statistiques de cette dernière sont pour le moins complexes, dans notre cas nous y avons recours notamment parce qu’elle est la plus à même de tracer une courbe de tendance sur une série de données.
Ce faisant, nous constatons que la thématique “Peur et sidération” ne connaît guère de fluctuation majeure, même si elle tend quelque peu à baisser en intensité à la moitié du documentaire. Une baisse malgré tout très relative. Cet axe constitue une forme de toile de fonds, avec différentes variantes, allant de la peur relative à la pandémie de Covid-19 jusqu’à la peur suscitée par les réactions des gouvernements à la crise sanitaire. À maints égards, cette dernière tend, le plus souvent, à prendre le pas sur la première, avec un entremêlement de visions du monde, plus ou moins alternatives, donnant à penser que cette peur généralisée loin d’être fortuite, serait la résultante d’une forme d’entente internationale. Une forme de stabilité dans le temps également pour les thématiques “Élite mondiale” ou encore celle consacrée à l’action du gouvernement. En termes de rupture de tendance, la thématique vaccinale connaît une rupture assez nette à partir du milieu du documentaire. L’autre rupture notable concerne le protocole Raoult.
Une analyse acoustique du documentaire
Pour aller plus loin dans nos analyses du documentaire nous avons également procéder à une analyse de la bande son, en nous inspirant des travaux réalisés par les chercheurs spécialisés en musicologie.
Le rôle de la musique de fond dans Hold-up occupe une dimension stratégique. Cela n’a rien d’étonnant, et s’inscrit dans une lignée de documents vidéos, amateurs pour l’essentiel, réalisés ces dernières années et mis en ligne sur les réseaux sociaux, et tout particulièrement sur YouTube. À cet égard, et pour l’exemple certainement le plus connu, rappelons l’utilisation, de manière répétée, de la bande originale du film Requiem for a Dream, composée par le britannique Clint Mansell, et qui a servi, à maintes reprises, de fond sonore à des vidéos relayant des discours alternatifs. Paradoxalement, bien que cette dimension acoustique soit une composante forte de ce que nous pourrions qualifier de culture populaire associée aux discours alternatifs, le champ associant l’exploitation des dimensions acoustiques au service de la construction de narratif, semble encore relativement peu exploré.
À cet égard, la manière dont le fond sonore est utilisé dans Hold-up, que ce soit via des accélérations brutales ou, au contraire, sur un schéma davantage lancinant, au point ou la musique semble voler la vedette aux intervenants, nous semble constituer un élément intéressant en termes d’heuristique. Après avoir visionné le documentaire à plusieurs reprises, en nous attachant notamment aux passages les plus saillants, nous avons émis le postulat, de manière purement impressionniste, que l’utilisation du fond sonore loin d’être anodine, et le contraire aurait été étonnant, est au service du narratif. En d’autres termes, loin d’être anecdotique ou subsidiaire, cette dernière contribue à créer un environnement, à créer des cadres non sémantiques et non discursifs, qui n’en concourent pas moins à créer un meta frame sur le discours déroulé par chacun des intervenants. La musique instrumentale utilisée dans le documentaire nous semble donc constituer un instrument, plus ou moins subtil, au service du propos global.
Pour analyser plus en avant cette hypothèse et ce postulat, impressionniste et empirique, nous avons mis en place un protocole spécifique afin de pouvoir exploiter en analyse de données les signaux sonores du documentaire. Nous exposons ci-dessous la démarche que nous avons suivi, en soulignant tout à la fois ses avantages, ainsi que ses écueils potentiels
- Le point de départ est constitué, fort logiquement, par la récupération du fichier multimédia du documentaire ;
- Notre fichier source est un .mkv de 3,82 gigaoctets (Go) ;
- Nous avons utilisé le logiciel Adobe Premiere Pro pour séparer la bande son, de la partie vidéo. Le résultat obtenu de ce split est un fichier au format .mp3 ;
- Ce fichier son a néanmoins l’inconvénient d’agréger l’ensemble des sons, qu’ils soient vocaux ou instrumentaux, ce qui rend donc son exploitation inopérante. L’enjeu était donc pour nous de parvenir à isoler la partie instrumentale du reste du fichier ;
- Dans un premier temps, nous avons essayé de procéder à ce split via Adobe Audition en utilisant un effet d’imagerie stéréo, devant permettre, en jouant sur les décibels et autres réglages, de supprimer la voix. Cette démarche n’a pas été concluante ;
- Toutefois, ce premier échec nous a mis sur la piste de la solution. En effet, en analysant, toujours via Adobe Audition, la fréquence et la hauteur de ton spectrale il nous est apparu logique que ce que nous mêmes ne pourrions arriver à réaliser, un modèle de machine learning sophistiqué pourrait l’obtenir ;
- Pour ce faire, nous nous sommes reposés sur les modèles pré-entraînés par Deezer et rendus publics sur la page GitHub de l’entreprise spécialisée dans le streaming musical. Spleeter est écrit en Python et utilise Tensorflow, l’outil open source développé par Google Brain qui permet de réaliser de l’apprentissage automatique. Tensorflow est tout particulièrement utilisé par les chercheurs, que ce soit via R ou Python, pour des travaux de classification d’images ou de catégorisation textuelle. Développé par des chercheurs de Deezer, Spleeter a l’insigne mérite de pouvoir s’utiliser directement en ligne de commande et permet d’obtenir séparément les fichiers suivants : vocals.wav et accompaniment.wav. (@spleeter2019) ;
- L’output obtenu est un Waveform Audio File Format et peut être lu via R. Pour ce faire, nous avons utilisé le package monitoR qui permet d’obtenir sous forme de données exploitables des signaux sonores (@monitoR) ;
- Ce package nous a permis d’obtenir dans un tableau de données la fréquence sonore associée à l’horodatage ;
- Un écueil s’est toutefois posé concernant l’exploitation de ces données. La tableau obtenu étant ainsi composé de plus de 400 millions d’entrées, cela rendait son traitement et son exploitation, notamment en termes de représentation graphique, pour le moins ardue. En effet, le champ de la recherche en acoustique, et par rapport aux travaux que nous avons pu consulter dans le cadre de la rédaction de cet article, se concentre essentiellement sur des passages de quelques secondes, voire quelques minutes ;
- Pour y remédier nous avons réalisé 4 chunks dans nos données, en utilisant la fonction slice du package dplyr (@dplyr). Les données d’horodatage présentes dans notre tableau étant de l’ordre de la milliseconde, nous avons transformé ces dernières pour les arrondir à la minute. Cet arrondi à la minute, et non à la seconde, répond à des enjeux de puissance de calcul et de lisibilité des analyses graphiques pouvant être réalisées. Les données de fréquence sonore étant, tout à la fois, positives et négatives, nous avons pris le parti de les rendre toutes positives. Ce choix, qui peut sembler étonnant en termes de méthodologie, n’est toutefois pas fortuit. L’amplitude d’un son, contrairement à son absence (Y=0), est donc tout à la fois au-dessus et en-dessous de 0. Les valeurs positives sur l’axe des ordonnées indiquant la compression, tandis que les négatives indiquent quant à elles la raréfaction (notre comphrénesion du rôle des valeurs positives et négatives dans l’analyse de l’amplitude sonore doit beaucoup à cet échange mis en ligne sur stackoverflow). Nous avons donc choisi de réaliser une moyenne groupée sur la minute des différentes valeurs obtenues, afin d’être en mesure de restituer sur l’horodatage du documentaire les séquences avec fond sonore et celle sans fond sonore. De même, et bien qu’on puisse considérer qu’une moyenne réalisée par minute, altère quelque peu la granularité des données, le résultat obtenu restitue bien l’intensité des séquences sonores diffusées dans le documentaire.
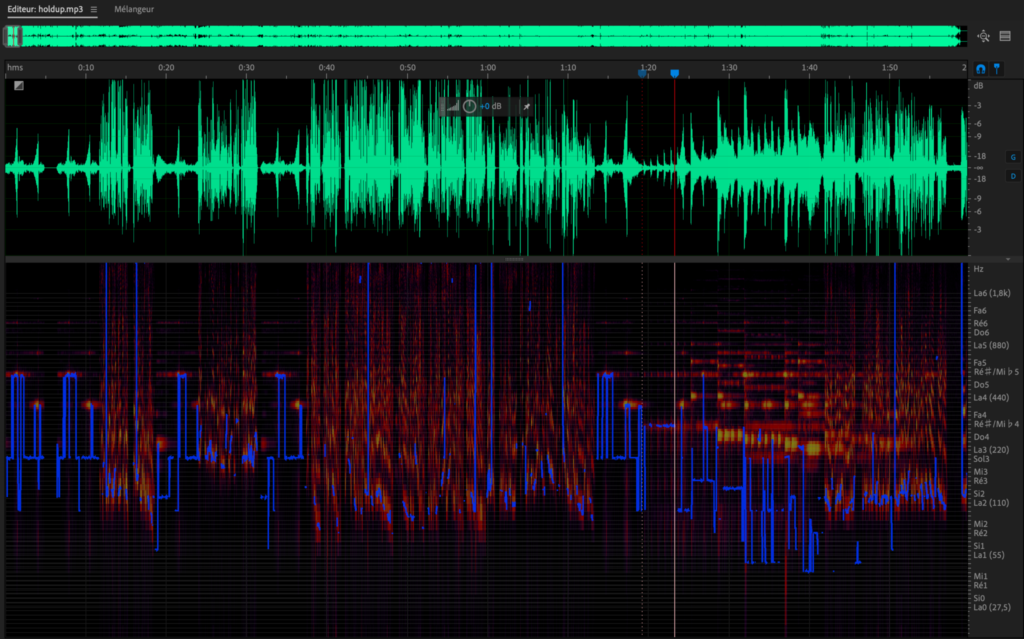

Cette représentation graphique, avec l’utilisation de la fonction geom_jitter(), qui permet d’éviter un chevauchement des points, en les agitant quelque peu, représente donc l’intensité sonore de la partie instrumentale du documentaire. Le terme d’intensité que nous utilisons n’est pas forcément le plus adéquat pour qualifier le phénomène étudié, mais il a le mérite d’être intelligible et de permettre une bonne caractérisation de l’utilisation faite dans Hold-up de la musique.

En utilisant, à nouveau, une régression loess, nous pouvons essayer de restituer la courbe générale de la tendance relative à l’intensité sonore tout au long du documentaire. Le graphique ci-dessous donne ainsi à voir une bascule à la moitié du documentaire. Après une entrée en matière assez marquée, le fond sonore se fait plus discret entre 00:30:00 et 01:00:00. Ce reflux de l’intensité sur cette séquence d’environ 30 minutes n’est pas anodin. Elle est ouverte par le discours de Michael Levitt, biophysicien, chimiste et prix Nobel de chimie, sur la non-dangerosité du Covid-19, basée sur une analyse de la situation à bord du Diamond Princess. Levitt explique que 3.700 passagers étaient à bord du bateau de croisière en février 2020, et tout en soulignant l’extrême densité de ce type de navire, qui serait quarante fois plus dense que Hong Kong selon lui, le prix Nobel souligne qu’en dépit de cette configuration seules 20% des personnes ont été infectées (700 personnes) et seules 7 personnes seraient décédées. Un discours qui, sur des bases logiques, statistiques et par là même rationnelles, tend à relativiser la dangerosité, dans l’absolu, du Covid-19.
“Je suis beaucoup plus effrayé par mon gouvernement, que je ne le suis par le virus. 10 fois plus et je ne me suis jamais senti comme cela avant” (Michael Yeadon, ancien directeur de la recherche chez Pfizer)
Un discours qui, en un sens, est résumé par ce propos de Michael Yeadon, qui tend à renverser la focale de la dangerosité du Covid-19 sur la dimension politique davantage que sanitaire. S’en suit un discours pointant du doigt les supposées incohérences du gouvernement, notamment sur la thématique des masques, qui n’apporte en la matière rien de nouveau par rapport aux discours qui ont eu cours ces derniers mois quant à la gestion de crise du gouvernement, et qui aboutit à la mise en avant du protocole Raoult.
Les intervenants qui se succèdent sur cette séquence sont tous des experts sur leurs thématiques, et par là même capables de créer un cadre propice à la confiance du fait de l’autorité de l’émetteur : Christian Perronne est ainsi professeur des universités-praticien hospitalier et spécialiste des maladies infectieuse. Pascal Trotta est radiologue. Violaine Guérin, quant à elle, est endocrinologue et gynécologue. Luigi Cavanna est directeur du service oncologie de l’hôpital de Piacenza. Gonzague Retournay est cardiologue. Parmi les personnalités politiques qui interviennent sur cette séquence Philippe Douste-Blazy, ancien ministre de la Santé, est la plus importante. À noter également la présence de Martine Wonner, ancienne députée de la majorité (exclue en mai 2020) et psychiatre. Seuls tranchent au milieu de cette liste les profils de Jean-Dominique Michel, qui serait selon Conspiracy Watch proche de la mouvance conspirationniste francophone, et d’Olivier Vuillemin, présenté par les auteurs du documentaire comme “expert en fraude scientifique”, mais dont les traces numériques le concernant, notamment en termes de publications, sont quasi inexistantes.
En un sens, et par-delà les cheminements propres à chacun des individus, notamment concernant Christian Perronne, considérés comme partisan de théories alternatives et que le quotidien Le Monde a qualifié le 18 novembre 2020 de “médecin référent des complotistes”, cette partie du documentaire peut-être considérée, en un sens, comme légitimée par la présence d’invités dotés d’une certaine autorité académique, scientifique ou encore politique. Elle reprend le discours des partisans de Didier Raoult, dénonce l’action du gouvernement, que ce soit sur les masques ou sur l’hydroxychloroquine, et tend à considérer, comme l’a fait tout au long du second semestre 2020, le camp dit des “rassuristes”, le Covid-19 comme bien peu dangereux. Un discours critiquable, mais qui avait déjà le droit de cité, à longueur de journées sur les chaînes d’information en continu, notamment sur Cnews et LCI. Dès lors, que le fond sonore se fasse moins présent peut s’expliquer par une volonté des auteurs du documentaire de ne pas mettre spécifiquement l’emphase sur ces propos qui n’ont pas forcément, de par leur dimension quelque peu éculée, la capacité de provoquer un effet de choc auprès des spectateurs. Il n’y a ni révélation fracassante, ni propos nouveaux, sur cette séquence, uniquement une reprise, reformatée certes, de l’air ambiant.

En représentant l’intensité du fond sonore par séquence de 10 minutes, plus à même de restituer une tendance générale, nous observons donc que la musique occupe, bel et bien, une place relativement faible dans la première partie du documentaire. Si la partie introductive offre une place importante à la musique, cette dernière baisse en intensité, laissant ainsi davantage le champ aux propos tenus par les intervenants de cette première séquence. À maints égards, et de l’avis général des observateurs ayant regardé le documentaire, ainsi que du nôtre, la première séquence du documentaire reprend donc des éléments relativement éculés, que ce soit sur la dangerosité effective du Covid-19, le confinement ou la problématique du port du masque, sans pour autant présenter des thèses alternatives complexes, faisant de la pandémie le résultat d’un complot. Cette bascule n’intervenant que sur la seconde partie du documentaire, reléguant le discours scientifique au second plan pour aborder des thématiques comme la 5G, les vaccins, les nanoparticules ou encore la dématérialisation de l’argent, véritable “hold-up” qui a donné son nom au documentaire.

En regroupant par séquence de 10 minutes les 02:30:00 du documentaire, et en appliquant pour chacune d’elles une analyse par TF-IDF (terme frequency-inverse document frequency) nous pouvons analyser la manière dont le documentaire se découpe en séquences saillantes, et plus ou moins propres et exclusives. Cette analyse, complémentaire de celle sur l’intensité, tend à renforcer l’idée d’une cassure à 01:30:00, avec une focale mise sur la question des laboratoires.

Ce faisant, il est possible, toujours en utilisant la méthode de pondération qu’est le TF-IDF de découper le documentaire en une séquence dite avant 01:30:00 et une autre dite après 01:30:00. Situation dans les hôpitaux et les services de réanimation, chiffres relatifs à l’épidémie et au nombre de malades, port du masques, protocole dans les lycées, et parallèle avec la précédente crise sanitaire de 2009, la première partie du documentaire ne fait rien apparaître, selon ce scoring, de très dissonant par rapport à ce qui se disait jusque-là dans la presse, les chaînes d’information en continu ou encore les réseaux sociaux quant au Covid-19. Cela ne veut aucunement dire de notre part que le discours en question ne revêt pas une quelconque dimension problématique, toutefois, et comme nous l’avons déjà exposé précédemment, il peut être considéré comme une resucée de l’air du temps. A contrario, la séquence post 01:30:00, avec notamment le pic d’intensité de 01:40:00, tend à sortir du champ purement sanitaire. En témoigne les mentions de Google, d’Apple et plus généralement des acteurs de l’industrie numérique. La mention de la 5G est également propre à cette séquence avec tout ce que cette thématique peut susciter dans l’opinion. À noter également le score de l’item “naturel”, qui montre que cette partie tend à questionner les origines fortuites, ou non, du Covid-19.
Quitte à être schématiques, et par là même nécessairement caricaturaux, nous pourrions dire que là où la séquence allant jusqu’à 01:30:00 se contente de reprendre, de reformuler et de recadrer, avec plus ou moins d’emphase, le discours somme toute mainstream sur le Covid-19, la seconde est davantage alternative. Elle aborde allégrement des terrains minés, notamment sur l’origine du Covid-19, et chemine sur la ligne de crête de thématiques pour le moins douteuses, en ce qu’elles donneraient à penser que le Covid-19 s’inscrirait dans le cadre d’un projet politico-économique d’une supposée élite mondiale.
La cassure, que nombre d’observateurs ont pressenti en écoutant le documentaire, est donc tout à la fois d’ordre sémantique et d’ordre acoustique. Si nous pourrions postuler que l’acoustique est nécessairement secondaire par rapport au sémantique, ce raisonnement reviendrait à faire fi du montage en post-production du documentaire. En d’autres termes, il est difficile de déterminer si le sémantique précède l’acoustique ou inversement, dans la mesure où les deux dimensions relèvent d’un construit artificiel. Quoi qu’il en soit, la dimension professionnelle de la réalisation du documentaire, et l’expérience de son réalisateur, qui compte de nombreux autres films à son actif, tendent à renforcer l’idée de choix délibérés en matière d’intensité sonore
Les 10 principaux temps forts
| time | intensity |
|---|---|
| 02:31:00 | 5846.189 |
| 02:40:00 | 5806.258 |
| 00:02:00 | 4214.305 |
| 02:16:00 | 4134.379 |
| 02:41:00 | 3867.037 |
| 02:15:00 | 3560.799 |
| 02:30:00 | 3536.514 |
| 01:23:00 | 3352.720 |
| 01:45:00 | 3138.133 |
| 01:44:00 | 3050.933 |
| 01:18:00 | 3003.212 |
| 01:35:00 | 2911.849 |
| 02:27:00 | 2845.080 |
| 01:43:00 | 2804.844 |
| 02:37:00 | 2756.668 |
| 02:33:00 | 2731.624 |
| 01:41:00 | 2565.031 |
| 02:09:00 | 2528.686 |
| 02:29:00 | 2405.257 |
| 02:03:00 | 2388.329 |
Le tableau ci-dessus représente les 10 principales séquences de 1 minute présentes dans le documentaire, et correspondent donc à une utilisation importante de la musique. À ce stade, deux enseignements peuvent être mis au jour, dans la continuité des précédents constats :
- Une bascule manifeste entre 01:28:00 et 01:20:00 ;
- Une utilisation soutenue dans la partie finale du documentaire notamment entre 02:25:00 et 02:26:00.
Pour rattacher chacune de ces séquences à une phase précise du documentaire, nous avons réalisé la liste ci-dessous qui, outre le fait de pouvoir permettre d’associer une séquence à un passage dans le documentaire, témoigne également que notre travail liminaire sur la structuration et les choix que nous avons faits quant à l’exploitation de nos données n’ont pas créé de faux positifs.
Séquence n°1 : Mise en avant de Florian Gomet et ouverture sur une dénonciation de la science (02:31:00)

Figure 2: Présentation d’un livre critique contre l’industrie pharmaceutique accusée de corruption des services
de santé
Cette séquence, s’ouvre par la mise en avant d’un livre qui, de par son titre, tend à assimiler l’industrie pharmaceutique à une sorte de mafia. L’auteur Peter C. Gøtzsche, présenté comme directeur du centre de recherche Cochrane Nordic, est interviewé dans le documentaire. Sans être un personnage controversé, comme peuvent l’être certains intervenants du documentaire, Peter C. Gøtzsche apparaît comme particulièrement dissonant et assez critique quant au fonctionnement de cette industrie. De manière plus problématique, dans un article publié le 24 mars 2020, il explique que la panique générale concernant l’épidémie de Covid-19, ne serait aucunement justifiée.
Au panomara relativement sinistre et noir que propose Peter C. Gøtzsche du monde pharmaceutique, les auteurs du documentaire propose une forme d’antidote, avec la mise en avant de Florian Gomet, un “aventurier hygiéniste” qui a couru à travers l’Europe après le premier confinement.

Figure 3: Florian Gomet, durant sa traversée de l’Europe après le premier confinement du printemps
“L’hygiène de vie adaptée à la physiologie de l’être humain permet de ne plus avoir peur des maladies. Aucune maladie. Aucun virus. Aucune bactérie (…) Le besoin de trouver quelque chose qui transcende la vie. Au départ je pensais le trouver à travers les mathématiques, la science et puis j’ai très vite réalisé que la science s’appuyait sur des dogmes, qui ne sont pas scientifiques, qui renient l’expérience que l’on peut vivre au quotidien, et ça c’est pas de la science. Alors j’ai préféré me diriger vers l’expérience, l’expérience du corps humain, l’expérience de la vie.” (Florian Gomet, décrit par les auteurs du documentaire comme “un jeune explorateur français”. C’est nous qui soulignons)
Un discours anti-science, qui sur certains points ne manque pas de faire écho à celui de Thierry Casasnovas, YouTubeur et adepte de pseudo-sciences, dont les discours sur les manières de guérir le cancer, à base notamment de crudivorisme et autres jus de fruits ou de légumes, font actuellement l’objet d’une enquête judiciaire, notamment du fait de supposées dérives sectaires du YouTubeur disposant de près d’un demi-million d’abonnés sur la plateforme de vidéos en ligne. Florian Gomet est d’ailleurs relativement proche de Thierry Casasnovas, ce qui, sans tomber dans une logique de sophisme par accusation, témoigne de la dimension non-neutre, et consécutivement quelque peu problématique, de cette présentation de Florian Gomet comme une sorte d’antidote et d’épiphanie en fin de documentaire.
“À la sortie du confinement, il a pris ses jambes à son cou pour montrer qu’il existait, sans doute, d’autres solutions pour garder la peine santé. 3.500 kilomètres en courant. Sans argent, sans passeport, et dans une Europe renfermée sur elle-même. Un vrai défi. Un vrai exploit. Une autre façon de vaincre.” (Commentaire de la voix off, tandis que Florian Gomet est présenté en train de courir. C’est nous qui soulignons).
Le discours de la voix off pour commenter les exploits de “l’explorateur” ne cherche d’ailleurs aucunement à apporter une quelconque forme de nuance, au risque de tomber dans une forme de manichéisme. À la noirceur et à la corruption du monde politico-techno-économique, la lumière viendrait d’un aventurier, sillonnant pieds-nus l’Europe “renfermée sur elle-même”. Et qu’importe si l’emballement de la musique pour accompagner cette odyssée contemporaine se met au service d’un discours anti-science et, fatalement, pseudo-scientifique.
“Ce qui fait que j’ai quitté tout ça (ses années de recherches), c’est de me rendre compte que la santé c’était simple. C’est subtil, et comme toutes les choses subtiles il y a une petite part de complexité, mais la complexité c’est une incrémentation de simplicités. C’est des choses simples qui s’imbriquent les unes aux autres. (…) Ce qui est est compliqué en général c’est juste pour empêcher les gens de penser, ou au moins de s’approprier un savoir, donc on va utiliser des mots bien compliqués, bien abscons, pour parler de quelque chose qui est très simple. Aujourd’hui la science est devenue, en particulier la science du médical, une religion. Où il y a des apostats, des inquisitions. Les gens vont défendre mordicus des idées, qui sont des dogmes, qu’ils ne maîtrisent même pas” (Miguel Barthéléry. C’est nous qui soulignons).
Et s’il fallait douter de la portée de cette séquence anti-scientifique, le témoigne de Miguel Barthéléry, docteur en médecine moléculaire et adepte, comme Thierry Casasnovas, du crudivorisme pour guérir du cancer, vient dissiper toute forme d’ambiguïté. La mise en avant de Florian Gomet, en première lecture, semblait naïve, voire, quelque peu, simpliste. D’aucuns auraient pu penser qu’elle était même fortuite. Or, en analysant ce qui est dit, par l’intervenant, ce qui est dit par la voix off et ce qui se joue au niveau de la partie sonore, force est de constater que nous avons bel et bien affaire à un construit qui fait sens pour les auteurs du documentaire. Un construit qui fait d’autant plus sens que le commentaire qui suit, avec la dénonciation davantage intellectuelle du fait scientifique par Miguel Barthéléry, présenté comme un renégat du champ, et tandis que la musique baisse en intensité, donne la clé de lecture à cet empilement de sens.
Séquence n°2 : l’effroi face à l’élite mondiale et la montée en puissance de la résistance (02:15:00 à 02:30:00)
02:25:00 : Cette séquence intervient quelques minutes après l’un des moments forts du documentaire, constitué par le témoignage de Nathalie Derivaux (02:18:00), décrite par le documentaire comme sage-femme, et qui réagit notamment avec beaucoup d’émotion aux déclarations de Laurent Alexandre, faites en 2019 devant des élèves de Polytechnique et de Centrale Paris. L’intervenante souligne notamment l’effroi suscité par le discours, volontairement caricatural et hyperbolique de la part de Laurent Alexandre, sur une hypothétique future dichotomie entre les “dieux” de la technologie et les “inutiles”. Nathalie Derivaux, en larmes sur le plateau, explique que ce discours lui évoque l’Allemagne nazie.
Cette intervention est suivie d’une animation 3D affublant le virus d’un masque barré des items “PEUR” et “MENSONGE” (02:22:55), suivi d’une autre animation 3D présentant un coffre-fort, sur lequel est inscrit “HOLD-UP” et qui repose sur une marre de sang. À 02:30:06, le narrateur reprend son rôle, après l’effet de saturation et de sidération des trois séquences précédentes, et souligne que :
“Un virus qui a donc terrorisé le monde à une exception près, la bourse. Cherchez l’erreur. Fin 2019, la crise économique était pourtant bien là. L’arrivée du corona fera pleuvoir des centaines de milliards d’euros et de dollars. Soulagement de la population. Elle peut rester concentrée sur la peur du virus transmise par les autorités via les médias, et les annonces réptées dans tous les services publics. Sur le front en France, la résistance commence à sortir du bois” (Discours de la voix off – c’est nous qui soulignons les items).
Cette séquence est importante, car elle marque la reprise du fond sonore, sur la forme d’un crescendo, qui vient, par-là même, accorder une portée accrue au discours déployé par le narrateur. En parallèle de ce crescendo, les images représentées avec une succession entre la représentation 3D du virus et des données boursières déroulantes permettent d’accroître l’emphase mise sur les éléments prétendument sous-jacents de la crise sanitaire, et tout particulièrement leur supposée dimension tout à la fois boursière, économique et politique.
Alors que le documentaire présente un extrait de l’intervention d’André Comte-Sponville sur RTL, en date du 7 septembre 2020, où le philosophe explique ne pas avoir peur du Covid-19, en relativisant la situation présente avec la peste et les guerres de Religion connues en son temps par Montaigne, la musique s’emballe et atteint le paroxysme de 02:25:00.
“Mais en Allemagne, en Italie, en Espagne, tout comme aux États-Unis, des centaines de médecins se font entendre depuis plusieurs mois. Des commissions d’enquêtes extra-parlementaires sont créées. Dans la rue les Allemands montrent l’exemple et répondent à la menace de cluster en descendant par dizaine de milliers. En Suisse, des lanceurs d’alerte transforment leur salon pour remplacer des médias dogmatiques. Et que dire aussi de ce chef d’entreprise dont la chaîne YouTube a été fermée pour avoir données de vrais infos. Dans quel monde est-on entrés ?”.
Le pic d’intensité de la musique est donc là pour consacré la cristallisation d’une forme de résistance, mondiale, à une manipulation également mondiale. Le schéma est binaire, nous pourrions même le qualifier de quelque peu manichéen, mais il permet de sortir de toutes considérations d’ordre purement sanitaire, pour mettre la focale sur la dimension irrémédiablement politique de la crise sanitaire. Il permet également au narrateur de montrer que la société civile constitue, d’une certaine manière, l’antidote au plan général conçu prétendument par les élites mondiales.
Il faut cependant souligner que le profil des lanceurs d’alertes et autres membres de la société civile supposément en train de s’organiser contre la situation tout à la fois sanitaire et politique, est loin d’être anodin. En effet, les whistleblowers présentés dans cette séquence sont, surtout, des tenants de grilles de lecture façonnées par ce que, de notre point de vue, nous pourrions qualifier de pseudo-sciences, d’ésotérisme, voire de dérives sectaires.
Tal Schaller, Jean-Jacques Crèvecoeur et Silvano Trotta présentés comme l’incarnation d’une forme supposée de résistance aux actions entreprises par les gouvernements mondiaux, avec la complicité des “médias dogmatiques” ont un profil qui tranche quelque peu avec l’idée d’une réaction, non organisée, de la société civile. Le premier, Tal Scheller, est un médecin suisse tenant de médecines alternatives, pratiquant le chamanisme et le channeling. Selon le portrait qu’a fait de lui le compte Twitter L’Extracteur, il manifesterait un intérêt prononcé pour la “vie après la mort”. Selon ce compte Twitter, spécialisé dans la dénonciation des pseudo-sciences, il aurait créé en 1996 un Centre d’Éducation de Santé Holistique. Ce dernier aurait d’ailleurs fait l’objet d’une enquête policière en raison de sa supposée proximité avec la secte de l’Ordre du Temple Solaire (OTS).
Le second, Jean-Jacques Crèvecoeur, affirme être physicien, philosophe et expert en manipulation des foules. Dans un extrait relayé, toujours par le compte de L’Extracteur, il explique ainsi avoir été, dans le passé, sollicité par les services secrets belges pour participer à une vaste opération de manipulation de l’opinion, via les médias. Il anime également des formations, en ligne, et s’avère être un fervent militant anti-vaccination15. Dans un extrait vidéo relayé par L’Extracteur, Jean-Jacques Crèvecoeur, dans le cadre d’un conversation avec Thierry Casasnovas, YouTubeur influent et promoteur de pseudo-sciences, reprend à son compte la théorie selon laquelle le Covid-19 ne serait rien d’autre qu’une tentative de l’élite mondiale, de l’OMS à Bill Gates, de pucer la population via des vaccins. Il y décrit notamment l’existence supposée d’une “pieuvre” mondiale qui contrôlerait les ministères de la Santé dans le monde au service de cet agenda devant permettre de paver la voie à la “mise en place de la dictature 3.0”.


Quant à Silvano Trotta, il dispose notamment d’une chaîne YouTube ayant 173.000 abonnés et qui cumule 18 866 577 vues. Comme l’indiquent les deux graphiques ci-dessus, sa chaîne YouTube a connu une nette bascule à partir de mars 2020, période qui correspond en France à l’accélération de la circulation du Covid-19 et à la première expérimentation du confinement à partir du 17 mars.
Le 27 août 2020, Silvano Trotta a notamment relayé sur sa chaîne une vidéo intitulée “HOLD-UP”, et ayant pour description “Je vous présente le super film de mon ami Pierre”. Cette vidéo, d’une durée de 11 minutes et 02 secondes, a suscité, à date, 99 623 vues. Il s’agit, comme sa description l’indique, d’une présentation du documentaire résumé par “[s]on ami Pierre” Barnérias. Cette vidéo commence par une dénonciation, de la part de Silvano Trotta, de la censure qu’il subirait sur YouTube, avec une série de vidéos relatives au Covid-19 qui aurait fait l’objet d’une censure de la part de la plateforme. Le discours qui suit vise à dénoncer les critiques contre l’hydroxychloroquine, en soulignant, à nouveaux frais, l’étude rétractée du Lancet qui, selon l’auteur de la vidéo, aurait sonné le glas au niveau mondial du protocole proposé par le professeur Didier Raoult. La vidéo se poursuit par une critique de Karine Lacombe, cible habituelle et récurrente des partisans de l’hydroxychloroquine et des militants anti-masques, du fait de ses liens supposés avec “BigPharma”. À 6 minutes 40 secondes, Silvano Trotta introduit le projet de documentaire de Pierre Barnérias, en soulignant “comme le bon sens est mis à mal, j’ai un ami qui fait un film, qui va s’appeler Hold-up”. Il ajoute également au sujet de Pierre Barnérias, à destination des abonnés et des viewers de la chaîne, que “beaucoup d’entre vous le connaissent” déjà. Silvano Trotta explique également que Pierre Barnérias lui a proposé d’intervenir dans le documentaire.
Cette séquence ne se réduit donc pas à une simple volonté d’utiliser le ressort musical pour cristalliser, autant que faire se peut, l’opposition entre l’élite mondiale et la “résistance »de la société civile, mais vise également à mettre en avant les figures de cette résistance. Aucune de ces figures, particulièrement clivantes et marquées, ne figurent dans le documentaire, mais ce clin d’œil musical ne semble pas être anodin, comme l’indiquent les propos de Silvano Trotta sur sa proximité avec le réalisateur du film.
Séquence n°3 : aucun hasard, tout était prévu (01:23:00)
« Nous vivons dans des sociétés qui sont politiquement organisées autour de la corruption. Le principe de la corruption est un principe générateur, est une force motrice de nos sociétés politiques” (Valérie Bugault, docteur en droit privé, et dont l’un des articles sur le Covid-19, particulièrement problématique, a fortement essaimé dans les milieux alternatifs)
“Un virus hyper-puissant donc, jusqu’à transformer nos démocraties. Il était pourtant annoncé depuis des années et d’une façon précise. Non pas par des complotistes en manque de notoriété, mais par des blouses blanches devenues voyantes, et des cols blancs très prévoyants (Commentaire de la voix off après le discours de Valérie Bugault)
Cette séquence succède au discours de Valérie Bugault, et est marquée par un enchaînement, en toile de fond, de personnalités comme David Rockefeller, Bill Gates, Anthony Fauci ou encore Jacques Attali, dans un montage pour le moins douteux, et qui trouve une forme d’apothéose dans une recension d’un ouvrage préfacé par Alexandre Adler, paru en 2009 et intitulé Le Rapport CIA – Comment sera le monde en 2020 ?
« Pour savoir ce qu’on allait vivre 11 ans plus tard, en 2020, il suffisait de lire la page 250” (Commentaire de la voix off sur l’ouvrage préfacée par Alexandre Adler).

Figure 4: Extrait du livre commenté par la voix off
Et la séquence s’enchaîne avec un pic d’intensité sonore à 01:23:00, alors que la voix off évoque David Rockefeller et sa fondation, reprenant le discours donnant à penser qu’en définitive, tous les évènements de 2020 loin d’être le fruit du hasard, auraient été théorisés, prévus et anticipés en amont, par des personnages de l’ombre. Les bases sont ainsi posées, avec l’accompagnement toujours stratégique du fond sonore, pour présenter sous un jour, somme toute assez sombre, l’action de personnalités mondiales influentes, à l’image notamment de Bill Gates. Avec cette séquence, les auteurs du documentaire délaissent manifestement la forme de normalité, à nouveau au sens de reprise d’un discours éculé à longueur de journées qui prévalait dans la première partie, pour cheminer sur le terrain pour le moins miné des théories alternatives qui, depuis le début de la crise sanitaire, n’ont pas manqué de fleurir.
L’emballement de la musique pour accompagner cette séquence, avec en point d’orgue l’emphase mise sur rôle de Bill Gates dans les enjeux liés à la vaccination, ainsi que la présentation de ces investissements dans le monde des nanoparticules, n’a donc rien d’anodin. À nouveau, et comme pour les deux séquences étudiées précédemment, l’utilisation de la musique ici est faite à dessein. Elle vient créer une forme de halo propice au développement d’un discours édifiant. Si la question des masques, et des errements du gouvernement en la matière, n’a rien de très sensationnel, il n’en est pas de même pour un discours tendant, certes plus ou moins subrepticement, à faire accroire que la crise sanitaire ne saurait relever d’une quelconque forme de contingence.
En somme point de hasard, pour les auteurs du documentaire et le montage qu’ils proposent, mais bel et bien un ensemble cohérent.
Annexe


Quels sont les ressorts objectifs et quantifiables à l’origine de cette volonté de réguler les réseaux sociaux ?

Création d’un modèle de classification de tweets basé sur l’utilisation des lettres capitales dans une série de publications.

Entretien avec Jean-Christophe Gatuingt, co-fondateur de Visibrain, sur les bouleversements en cours sur les réseaux sociaux.

On s’inquiéterait, à juste titre, qu’un juriste puisse discourir doctement sans jamais avoir lu la moindre ligne d’un code civil ou pénal. Mais on ne s’inquiète pas d’une telle situation, tout aussi affligeante, dans l’univers des médias et de la communication.